-
Link to PaperHaving caregivers actively engage in child-directed speech, and providing face-to-face communication to their child, can play a central role in the child's language, cognitive, and social development over their lifetime. However, over 90% of Deaf and Hard of Hearing (DHH) children are born to hearing parents who might not know American Sign Language (ASL) and are faced with the potentially steep learning curve of a new language. With my dissertation work, I plan on investigating assistive communication technologies that can support caregivers in communicating with their DHH children. This work aims to explore design guidelines and hands-on prototypes that can bridge this communicative gap.
---
-
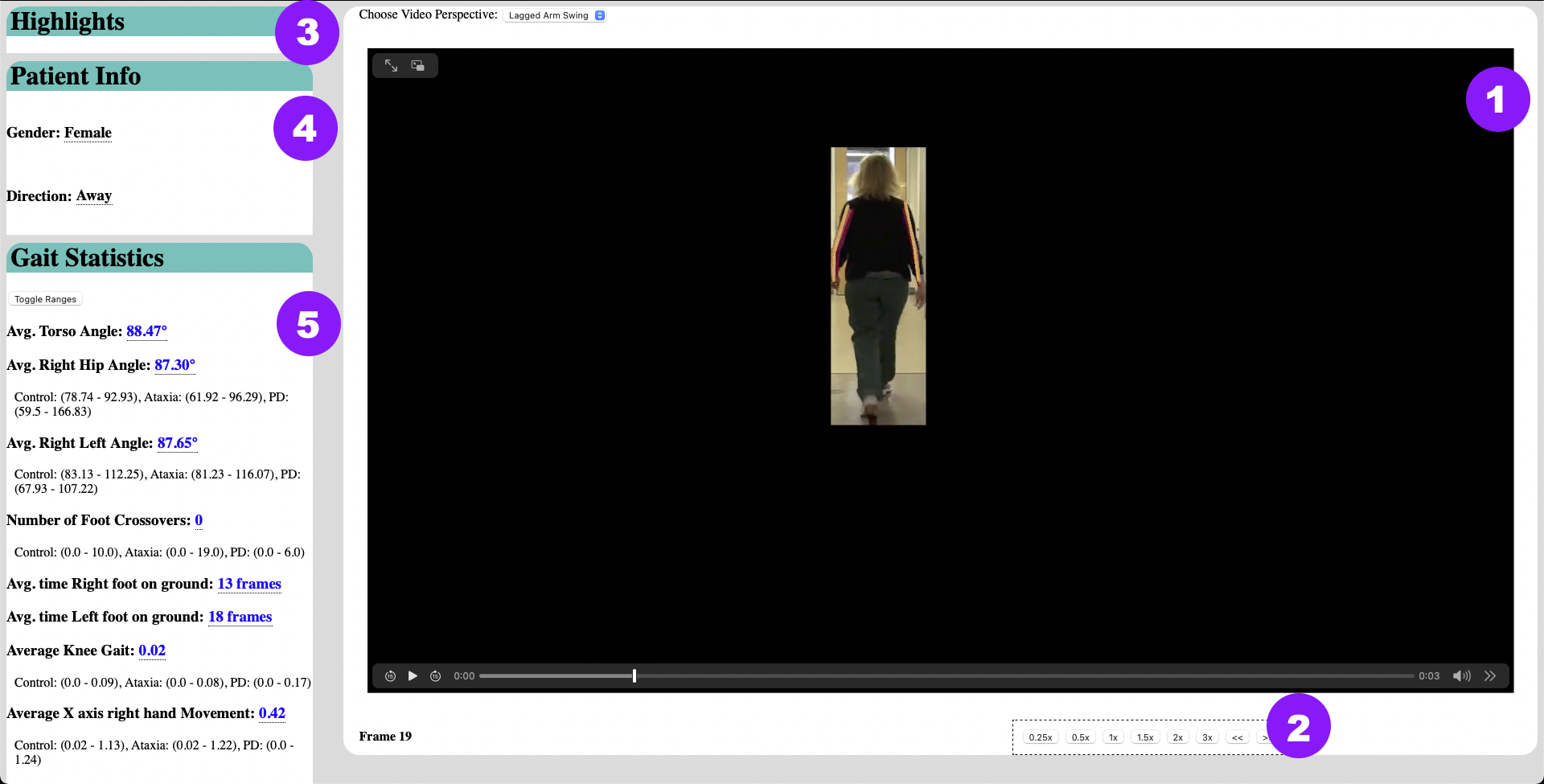
Link to PaperCurrently doctors rely on tools such as the Unified Parkinson’s Disease Rating Scale (MDS-UDPRS) and the Scale for the Assessment and Rating of Ataxia (SARA) to make diagnoses for movement disorders based on clinical observations of a patient’s motor movement. Observation-based assessments however are inherently subjective and can differ by person. Moreover, different movement disorders show overlapping symptoms, challenging neurologists to make a correct diagnosis based on eyesight alone. In this work, we create an intelligent interface to highlight movements and gestures that are indicative of a movement disorder to observing doctors. First, we analyzed the walking patterns of 43 participants with Parkinson’s Disease (PD), 60 participants with ataxia, and 52 participants with no movement disorder to find ten metrics that can be used to distinguish PD from ataxia. Next, we designed an interface that provides context to the gestures that are relevant to a movement disorder diagnosis. Finally, we surveyed two neurologists (one who specializes in PD and the other who specializes in ataxia) on how useful this interface is for making a diagnosis. Our results not only showcase additional metrics that can be used to evaluate movement disorders quantitatively but also outline steps to be taken when designing an interface for these kinds of diagnostic tasks.
---
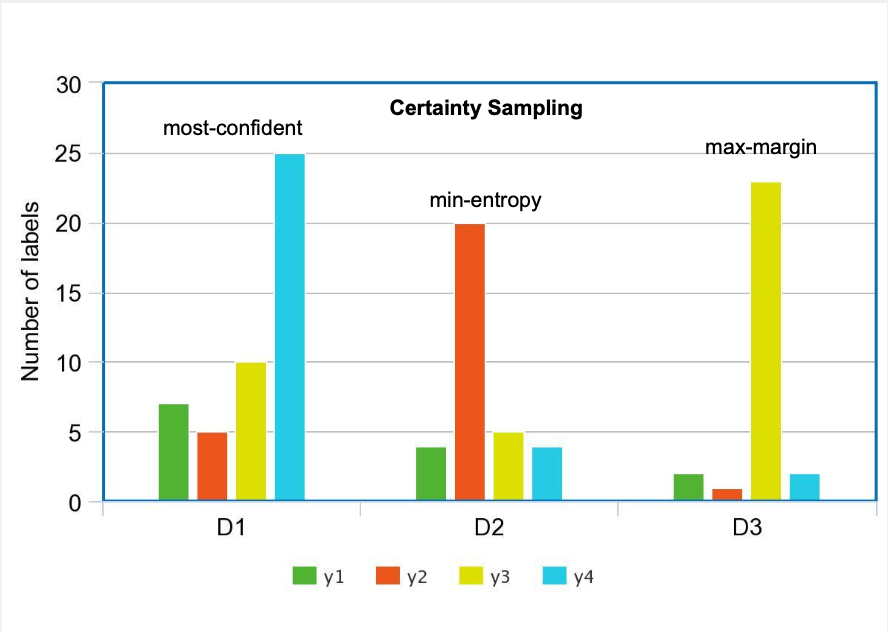
Some supervised learning problems can require predicting a probability distribution over possible answers than one (set of) answer(s). In such cases, a major scaling issue is the amount of labels needed, since compared to their single- or multi-label counterparts, distributional labels are typically (1) harder to learn and (2) more expensive to obtain for training and testing. In this paper, we explore the use of active learning to alleviate this bottleneck. We progressively train a label distribution learning model by selectively labeling data and, achieving the minimum error rate with fifty percent fewer data items than non-active learning strategies. Our experiments show that certainty-based query strategies outperform uncertainty-based ones on the label distribution learning problems we study.
---

The combination of gestures, intonations, and textual content plays a key role in argument delivery. However, the current literature mostly considers textual content while assessing the quality of an argument, and it is limited to datasets containing short sequences (18-48 words). In this paper, we study argument quality assessment in a multimodal context, and experiment on DBATES, a publicly available dataset of long debate videos. First, we propose a set of interpretable debate centric features such as clarity, content variation, body movement cues, and pauses, inspired by theories of argumentation quality. Second, we design the Multimodal ARgument Quality assessor (MARQ)–a hierarchical neural network model that summarizes the multimodal signals on long sequences and enriches the multimodal embedding with debate centric features. Our proposed MARQ model achieves an accuracy of 81.91% on the argument quality prediction task and outperforms established baseline models with an error rate reduction of 22.7%. Through ablation studies, we demonstrate the importance of multimodal cues in modeling argument quality.
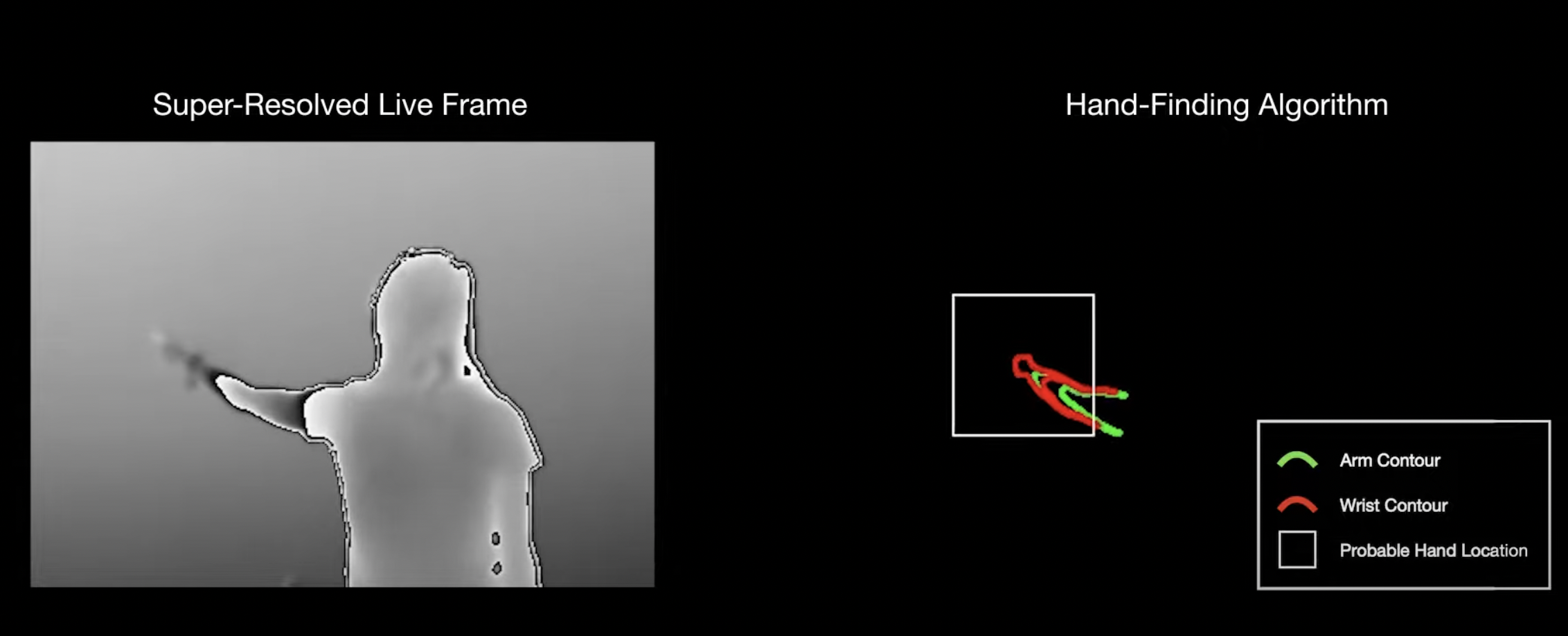
The ability to co-opt everyday surfaces for touch interactivity has been an area of HCI research for several decades. Ideally, a sensor operating in a device (such as a smart speaker) would be able to enable a whole room with touch sensing capabilities. Such a system could allow for software-defined light switches on walls, gestural input on countertops, and in general, more digitally flexible environments. While advances in depth sensors and computer vision have led to step-function improvements in the past, progress has slowed in recent years. We surveyed the literature and found that the very best ad hoc touch sensing systems are able to operate at ranges up to around 1.5 m. This limited range means that sensors must be carefully positioned in an environment to enable specific surfaces for interaction. In this research, we set ourselves the goal of doubling the sensing range of the current state of the art system. To achieve this goal, we leveraged an interesting finger ”denting” phenomena and adopted a marginal gains philosophy when developing our full stack. When put together, these many small improvements compound and yield a significant stride in performance. At 3 m range, our system offers a spatial accuracy of 0.98 cm with a touch segmentation accuracy of 96.1%, in line with prior systems operating at less than half the range. While more work remains to be done to achieve true room-scale ubiquity, we believe our system constitutes a useful advance over prior work.
Applications on the internet (ex. social media video streaming sites) want to create an engaging personalized experience but do so by sharing a user’s data without their direct knowledge. Users are not immediately aware of which institutions have access to their data, what kinds of new insight is being generated from that data, and what kinds of algorithms are being used on their data. The goal of our work was to create a tool that allows a user to explicitly state which algorithms can be used on their data and let the user audit how that data was used with different algorithms later on. This will help to build trust between users and their applications.
More here...