In the weeks following my last blog post, I had a niggling feeling that I could apply an MCP server to my literature review. This post is my first run at exploring that.
During my grad degree, it has been one of the hardest aspects I’ve had to learn: How do you take papers and distill them down to a supporting argument, a newfound gap, or evidence that something you want to build has a high chance of working? It’s initially really time consumptive, and to my surprise, isn’t a uniform process for labs and researchers. For me I have a massive Google sheet with a tab for each area I’m investigating, a column for each aspect I want to explore in that area, and a row for each paper I’ve found. With some starter papers in hand I’ll review the papers it cites (backwards pass) and the papers that cite it (forward pass) and add new papers to the spreadsheet based on relevance to the area. Another student I know tries to follow something similar to a PRISMA approach by reviewing a conference at a time, screening papers, and including works in their manuscript based on eligibility. Another student frantically searches keywords on Google Scholar right before the deadline (this is ill-advised).
However, not everyone takes this approach. Last year I reviewed a paper where every single citation was fake. All of them. It was not only a waste of my time, but if I hadn’t caught it, it could have been published and given false credibility to an idea that hadn’t been proven. This is one of the reasons why the pre-print site ArXiv announced they’re banning authors if they let LLMs generate the paper and ACL will desk reject papers with fake citations.
I think LLMs can have their place in the research process but the review of related work is what makes a work trustworthy and part of a solid foundation for others to use. There are some LLM tools that try to improve on the paper-finding process (Google Scholar Labs, Undermind.ai) but reproducibility of that search process still can be an issue and it can be unclear to see how a selected work fits into a broader scope of an area.
The jury is still out on how these models will be used in the future, but I was interested in how I could use one to make a tool to aid in my reviews.
Initial idea
I wanted to build a tool that helped me to make arguments but also was grounded in real research concepts and could be audited for correctness.
I started with my spreadsheet of papers I’ve already reviewed and decided building an MCP server that could review through those made sense. This way I also don’t have any real storage costs, since I could use the Google Docs API to “host” the detailed attributes of papers that I had already vetted. There’s 16 active-ish sheets with about 30 papers each, but I started with just four sheets (i.e. research areas).
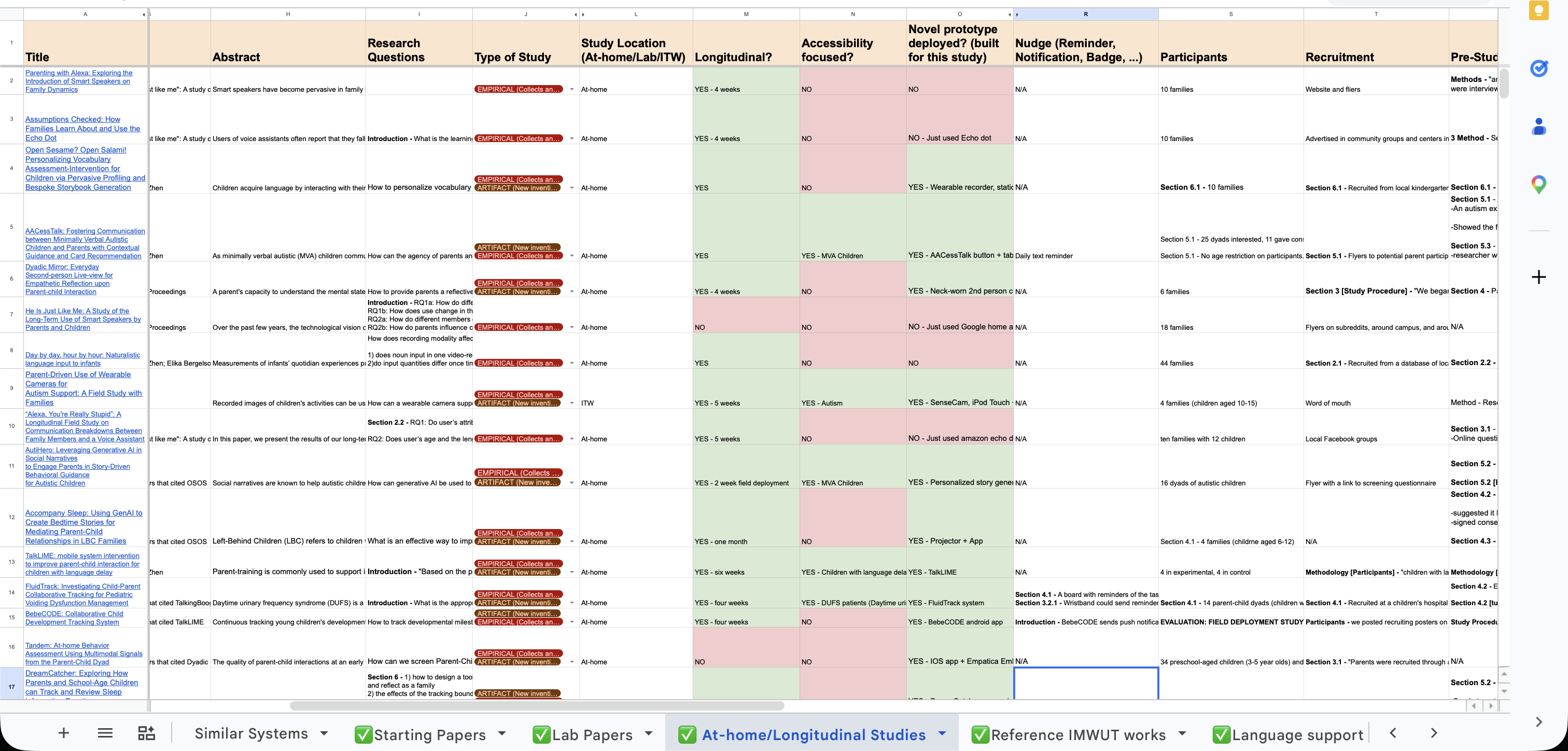 |
|---|
| A screenshot of my literature review spreadsheet on Google Sheets |
I used Claude to write a short Python script to create a basic MCP server that I could host on AWS Lambda (free tier!). The server had a function (technically called a tool) for each sheet and an additional prompt for a description of my prototype, my study goal, and my planned study procedure.
Once I wired the server into cursor, I gave it a go:
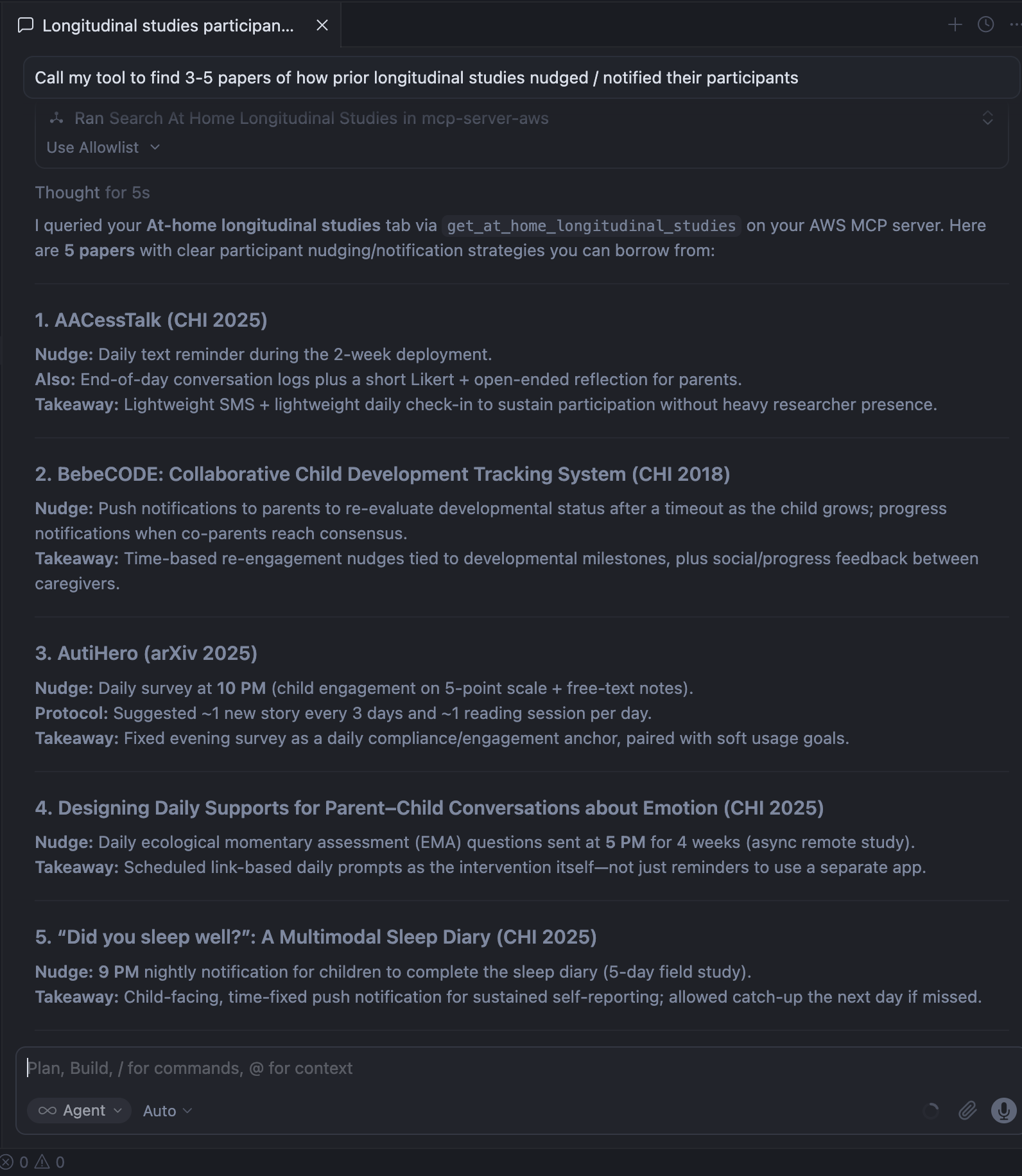 |
|---|
| Generating summaries of methods based on prior work I’ve reviewed |
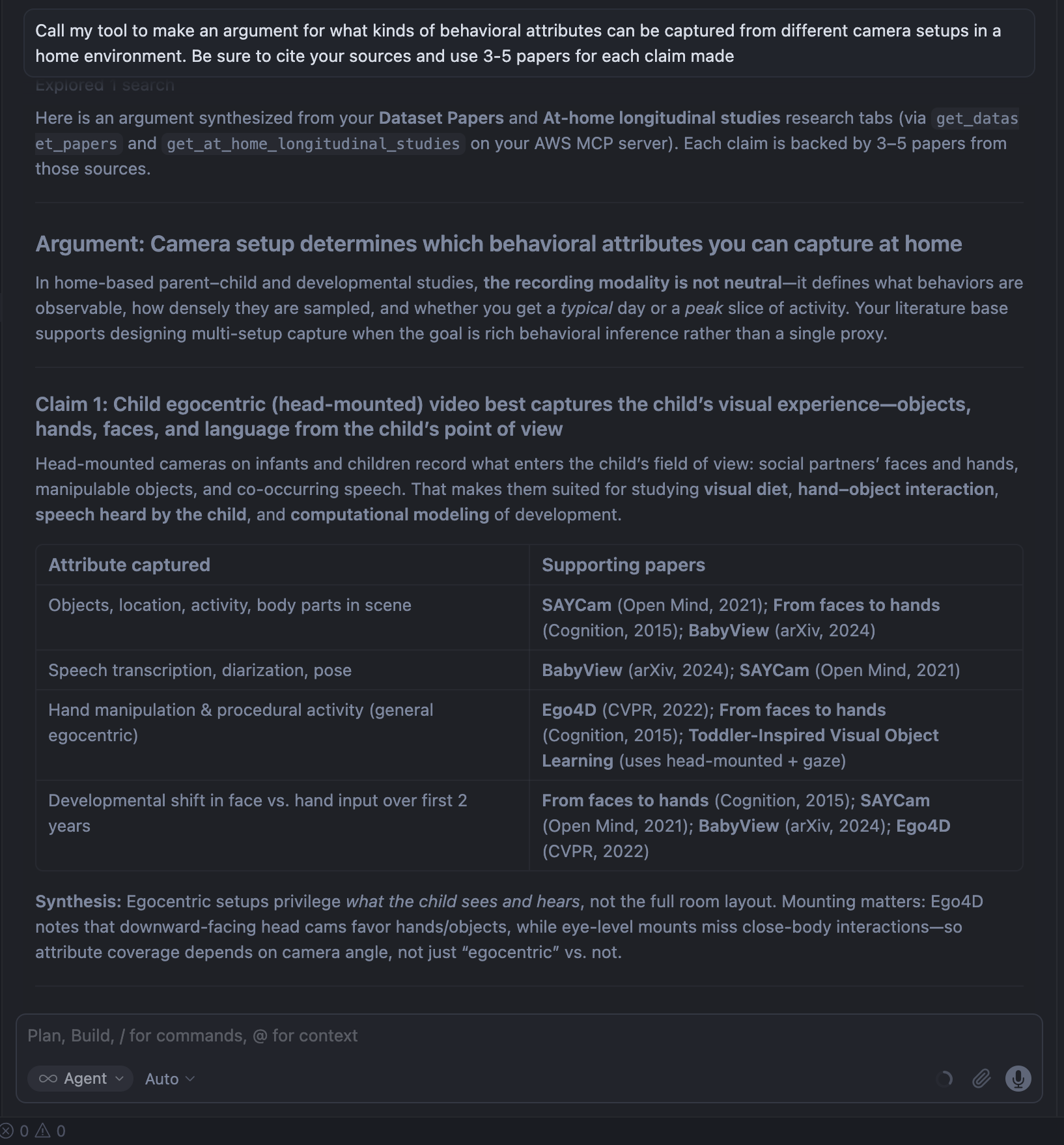 |
|---|
| Genrating arguments based on methods in prior work |
I like this because I know how it arrived at these claims and I know which papers I need to review if I want more details on them. Plus, if I make changes in my spreadsheet, it’s instantly reflected in my server. That being said, it isn’t perfect; The output is unstructured and some papers were repeated since I didn’t have a broad enough scope of that sub-area, but I think I could solve that with an updated review.
My next step was a new sheet/tab that holds all the gids (indicies in Google sheets to reference each sheet in the file) associated with an area. This made it so I could auto-generate a function that I could call for getting the papers from each area. I also added search functions so in addition to getting all of the papers in a given area, the server would allow the model to search a column of a specific sheet, which is particularly helpful on columns that are boolean values.
On device? At home?? Maybe later
 |
|---|
| Orange Pi could locally run the MCP server |
I have an Orange Pi in my apartment that could hold the full spreadsheet and the MCP server. I could also locally run an LLM, like Liquid AI’s LFM 2.5 or a Llama model, on my mac to call the MCP server. The really fun idea would be to have the server, when it’s not being used, screen new proceedings and email me a daily summary of things semantically (via keyword embeddings?) related to my study goals (currently a prompt in the MCP server). I currently have an RSS feed of ArXiv HCI and some SIGCHI conferences, but would appreciate this as another addition.
Llama, I Believe This Is The Beginning Of A Beautiful Friendship
Do I use this tool for research right now? No, it is still just a toy. I don’t think its a good idea to automate away all of the human curation that goes into building good science, but do like like the idea of aids and additions to improve (not necessarily speed up) human ability.
An LLM (Claude) was used to write the code for the MCP Server and advised on the setup and AWS implementation. This post was written and reviewed by a human (me!)